ASIC Acceleration for
Graph Convolutional Neural
Networks
A low-power, high-throughput ASIC module designed to accelerate GCN inference. By leveraging Coordinate List (COO) sparse matrix representations, this design minimizes memory footprint and maximizes computation efficiency through specialized Transformation and Combination phases.
GitHub RepositorySystem Architecture
High-level block diagram recreating the design from the milestone report.
graph LR
classDef default fill:#ffffff0d,stroke:#64ffda,stroke-width:1px,color:#fff;
classDef block fill:#00000066,stroke:#3b82f6,stroke-width:2px,color:#fff,line-height:1.5;
classDef mem fill:#8b5cf633,stroke:#8b5cf6,stroke-width:2px,color:#fff;
classDef input fill:transparent,stroke:transparent,color:#64ffda,font-weight:bold,font-size:16px;
Input1[data_in, start]:::input
Input2[COO_data]:::input
TB["Transformation Block
• FSM
• Vector Multiplier (16 Adders)
• Scratch Pad
• Weight Counter
• Feature Counter"]:::block CB["Combination Block
• FSM
• COO-Edge Selector
• COO-Node Selector"]:::block FMW[(FM_WM Memory)]:::mem FMA[(FM_WM_ADJ Memory)]:::mem AM[ARGMAX]:::block FO([Final Output]):::block Input1 --> TB TB -->|Writes| FMW FMW -->|Reads| CB Input2 --> CB CB -->|Updates| FMA FMA -->|Reads| AM AM -->|done| FO
• FSM
• Vector Multiplier (16 Adders)
• Scratch Pad
• Weight Counter
• Feature Counter"]:::block CB["Combination Block
• FSM
• COO-Edge Selector
• COO-Node Selector"]:::block FMW[(FM_WM Memory)]:::mem FMA[(FM_WM_ADJ Memory)]:::mem AM[ARGMAX]:::block FO([Final Output]):::block Input1 --> TB TB -->|Writes| FMW FMW -->|Reads| CB Input2 --> CB CB -->|Updates| FMA FMA -->|Reads| AM AM -->|done| FO
Performance Metrics
Measured post-layout using Synopsys DC and Cadence Innovus.
Latency
66.55ns
@ 15.03 MHz (Total End-to-End)
Power
4.81mW
Total Average Power
Area
20,980µm²
Standard + Filler Cells Area
Logic Size
29,978Gates
10,076 Standard Cells
Synthesis & Verification Results
Screenshots from Cadence Virtuoso and Post-Synthesis Simulation.
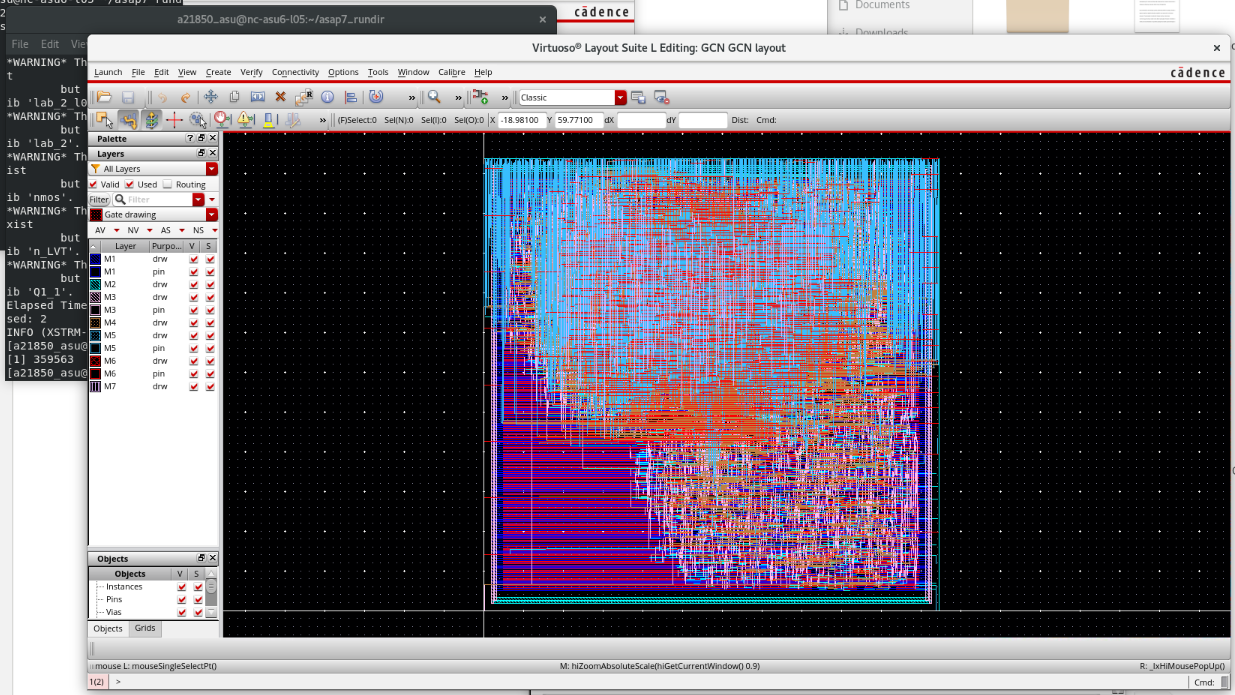
Virtuoso Layout
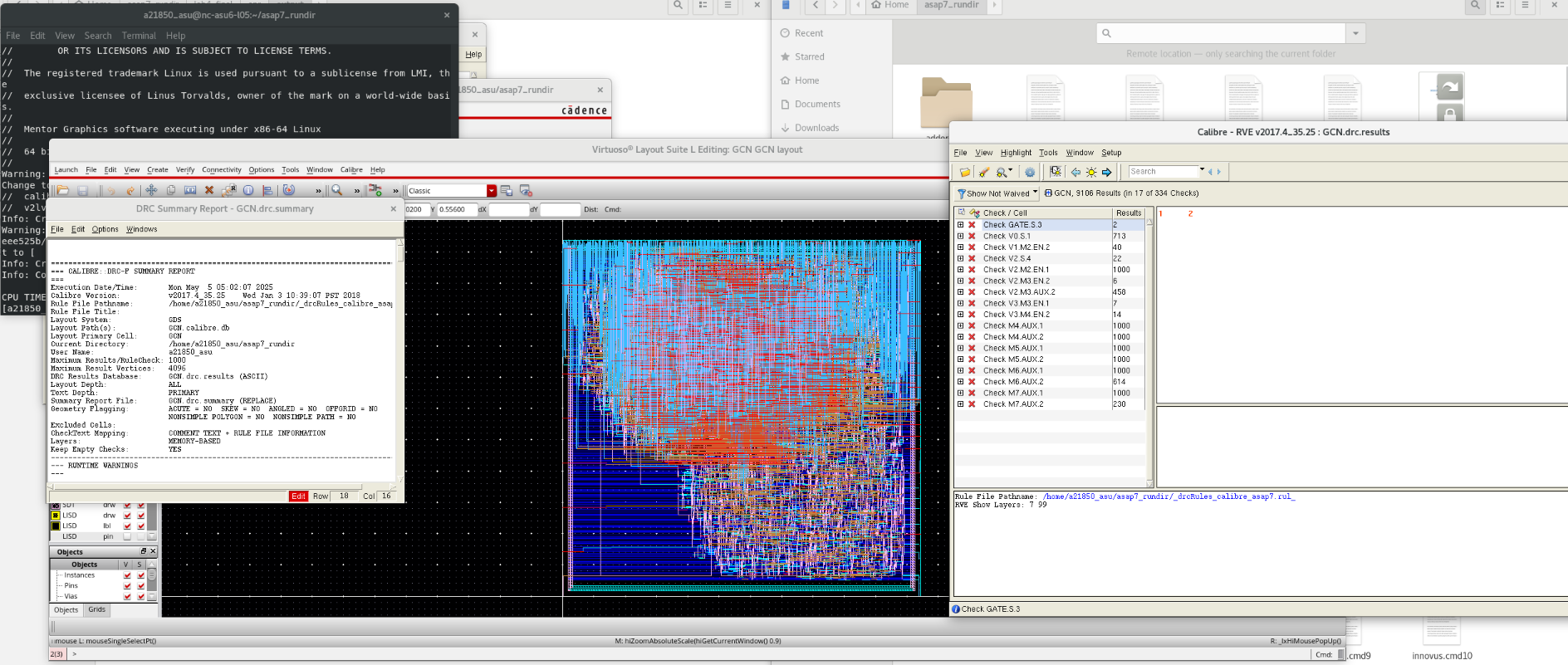
Design Rule Check (DRC)
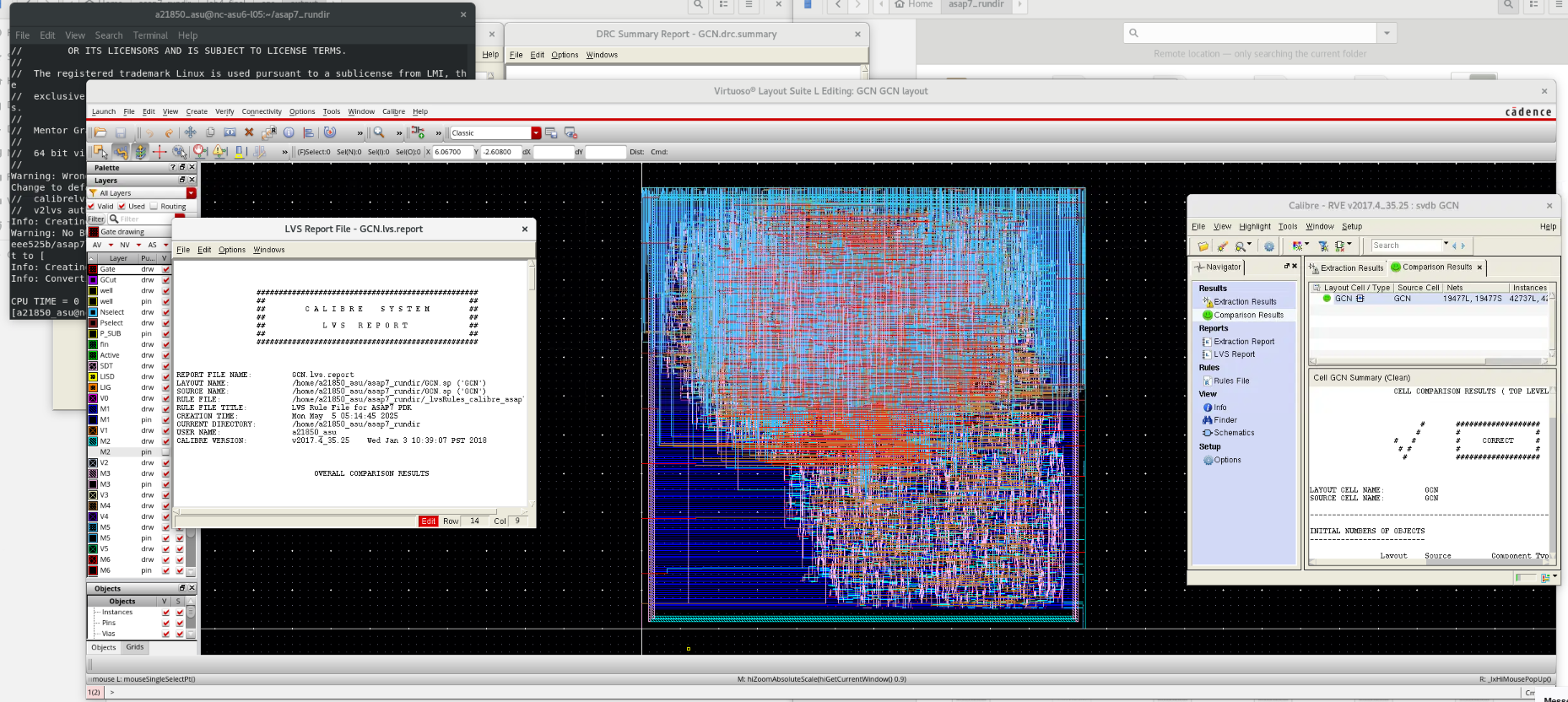
Layout vs Schematic (LVS)
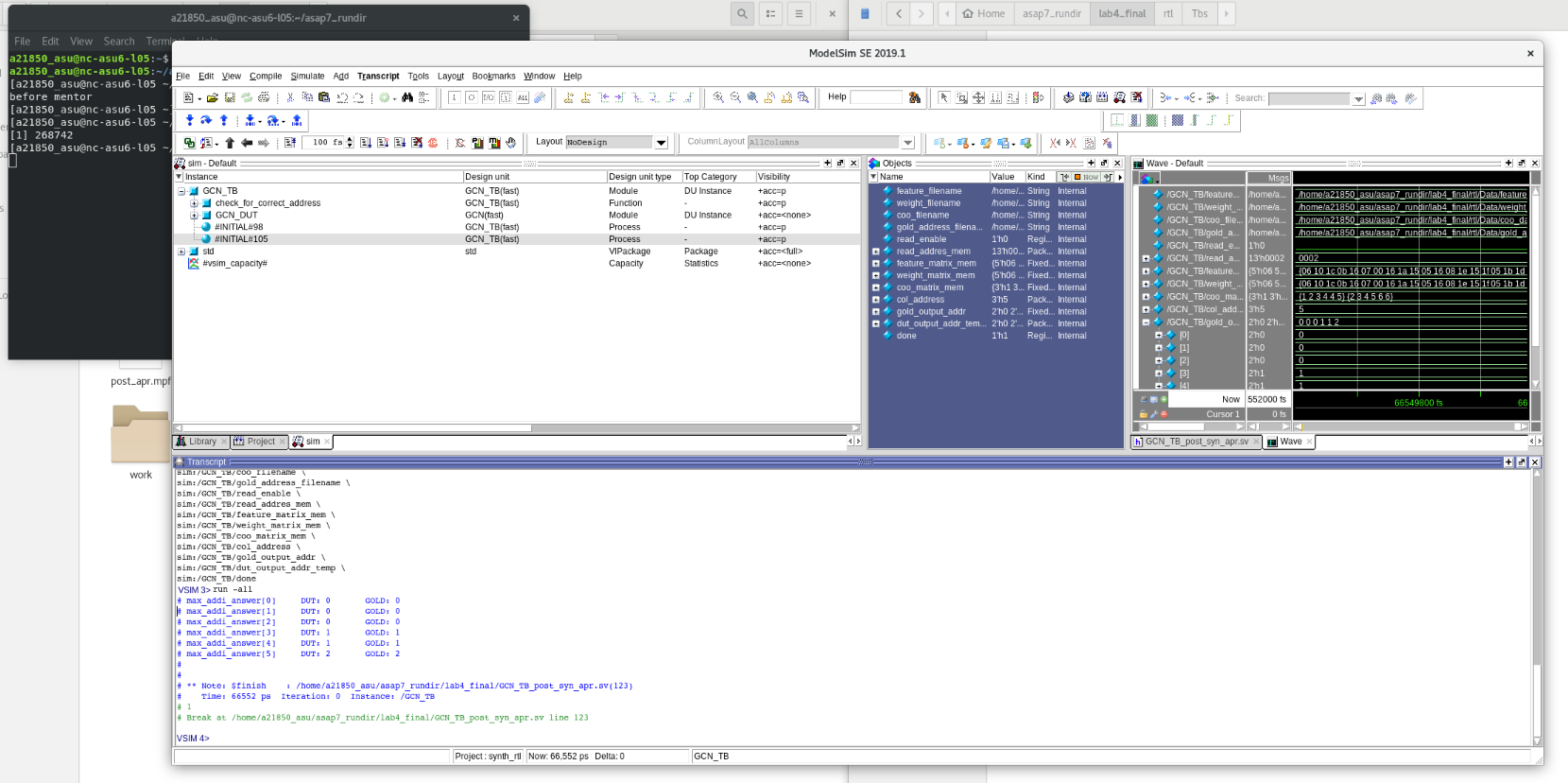
Post Synthesis Simulation